Veilig testen met geanonimiseerde data

Steeds vaker lees je dat privacygevoelige gegevens op straat komen te liggen door een datalek. Vaak komen deze gegevens rechtstreeks uit de productieomgeving van een applicatie maar recentelijk zien we echter ook voorbeelden van datalekken die zijn ontstaan omdat privacygevoelige data aanwezig is in een test of ontwikkeling omgeving van een applicatie. En dat is jammer omdat juist in deze niet-productie omgevingen privacygevoelige gegevens gemakkelijk en snel te beschermen zijn.
Testen met productiedata
Vanuit de gedachte van een tester die de functionaliteit van een applicatie moet beoordelen is er vaak niets beter dan testen met productiedata. De reden hiervoor is simpel: stel je gaat een nieuwe versie van een applicatie testen. Hiervoor maak je gebruik van een aparte testomgeving zodat je – voordat je de nieuwe versie naar productie brengt – kan testen of de nieuwe versie naar wens functioneert. Als je binnen de testomgeving gebruik maakt van dezelfde data als op productie en er treedt een fout op, dan kun je concluderen dat naar alle waarschijnlijkheid de fout ontstaan is door de nieuwe versie van de software en niet door bijvoorbeeld een fout in de data.
Hoewel dit scenario logisch klinkt, en dit voor veel organisaties nog steeds de manier is om software te testen, is er een probleem op het moment dat je binnen de applicatie persoonsgegevens verwerkt: in veruit de meeste gevallen is het niet toegestaan.
Waarom je niet met persoonsgegevens mag testen
De belangrijkste reden waarom je niet met persoonsgegevens mag testen heeft te maken met doelbinding. Doelbinding is een term die gedefinieerd is in de Algemene Verordening Gegevensbescherming (AVG). In principe komt doelbinding erop neer dat je als organisatie persoonsgegevens alleen mag gebruiken voor een “welbepaald, uitdrukkelijk omschreven en gerechtvaardigd doel”. Dat klinkt op dit moment misschien nog wat vaag dus laten we kijken naar een (versimpelt) voorbeeld.
Stel je werkt bij een webshop die fietsen verkoopt. Aangezien die fietsen uiteindelijk bij de koper thuis geleverd moeten worden heb je hiervoor een aantal persoonsgegevens nodig zoals naam, adres, woonplaats en een emailadres voor contact en updates rondom de zending. Dat je deze persoonsgegevens nodig hebt is prima te verantwoorden. Zonder deze gegevens kan een persoon wel een fiets kopen maar kun jij hem niet versturen. Tegelijk informeer je de kopers welke gegevens je nodig hebt en waarvoor je deze gaat gebruiken. Een prima voorbeeld van een “welbepaald, uitdrukkelijk omschreven en gerechtvaardigd doel”.
Stel nu dat er een nieuwe versie van de webshop applicatie beschikbaar is. Deze wil je uiteraard niet zonder testen zomaar online zetten dus je maakt een testomgeving van de webshop aan samen met alle data van klanten die ooit een fiets bij je gekocht hebben. Nu verandert het originele doel wat je had voor het verzamelen van de persoonsgegevens van de klanten. Het originele doel waarom je de gegevens nodig had – de gekochte fiets thuis afleveren bij een koper – is nu veranderd naar het testen van de nieuwe versie van de webshop applicatie. En daar hebben je klanten geen toestemming voor gegeven toen ze hun persoonsgegevens in je webshop registreerde.
Het voorbeeld hierboven is sterk versimpeld want vaak ligt het toetsen van doelbinding in de praktijk veel genuanceerder. Zo zou je het testen van software ook mogelijk uit kunnen leggen als een verenigbaar doel met de oorspronkelijke reden waarom je de persoonsgegevens hebt verzameld. Dankzij het testen van de software wordt de dienstverlening richting je klanten verbeterd en voorkom je eventuele fouten. Maar daarmee ben je er natuurlijk nog niet. Op het moment dat je persoonsgegevens verwerkt in een testomgeving zal je er ook voor moeten zorgen dat deze minimaal dezelfde beveiliging heeft als de productieomgeving. Dat betekent ook dat zaken zoals autorisaties en toegang gelijk moeten zijn. Zo mag een tester natuurlijk niet ineens alsnog gegevens inzien omdat hij of zij meer rechten ontvangt in de testomgeving.
Een manier om met doelbinding om te gaan is door aan al je klanten toestemming te vragen om hun gegevens te gebruiken voor testdoeleinden van je webshop applicatie. Dit betekent dat iedereen die een fiets bij je bestelt hiervoor expliciet akkoord op zal moeten geven. Daar komt bij dat hoogstwaarschijnlijk niet al je klanten willen dat je hun gegevens gebruikt voor het testen van je webshop applicatie. Hoe ga je dan bijvoorbeeld zorgen dat de personen die hier geen toestemming voor geven ook niet in de data van je testomgeving belanden? Tegelijkertijd veranderd hierdoor ook de inhoud van je testdata ten opzichte van productie waardoor “productie-like” testen mogelijk ook lastiger wordt.
En dan is er ook nog het risico op een datalek. Als de beveiliging van de testomgeving niet op orde is en er wordt ingebroken op de testomgeving kunnen kwaadwillende persoonsgegevens stelen en dat is helemaal niet nodig omdat het anders kan en moet. En helaas zien we dit toch met enige regelmaat voorbijkomen.
Een andere mogelijke oplossing is gebruik maken van fictieve testdata. Hierbij vul je je testomgeving met gegevens van fictieve personen en zorg je ervoor dat de data van echte personen verwijderd is. Hoewel deze oplossing ideaal lijkt kan dit wel tot mogelijke risico’s tijden het testen leiden. Dit komt omdat deze fictieve data niet gelijk is aan de data in je productieomgeving. Fouten bij het genereren van fictieve testdata kunnen leiden tot verkeerde uitkomsten van testgevallen. Die uitkomsten worden gebruikt om de kwaliteit van een nieuw of aangepast softwareprogramma te beoordelen, dus je kunt het je niet veroorloven dat het oordeel gebaseerd is op verkeerde uitkomsten. Ook dit is uiteraard op te lossen door veel tijd en aandacht te schenken aan je fictieve data zodat het zo “productie-like” mogelijk is maar bereid je voor op een grote tijdsinvestering die alleen maar toeneemt des te meer data je applicatie verwerkt.
Het voordeel van test data anonimiseren
Een van de oplossingen die de potentie heeft om zo “productie-like” mogelijk te testen zonder dat er privacy of test risico’s in je testomgeving blijven bestaan is anonimiseren. Hoewel er soms een beeld bestaat dat anonimiseren leidt tot onbruikbare data – vervang alle gevoelige data door X’en bijvoorbeeld, is dit lang niet de enige vorm van anonimiseren.

Het bekende “vervangen door onleesbare karakters” is wel één van de anonimiseer mogelijkheden maar lang niet de enige. Zo zijn er anonimiseertechnieken die bestaande data vervangen voor vooraf gedefinieerde data – bijvoorbeeld vervang alle emailadressen door test@privinity.com – en technieken die ruis toevoegen aan bestaande data zodat deze net even wat anders wordt dan de originele waarde – bijvoorbeeld verander een geboortedatum van 12-02-1993 naar 03-03-1993.
Door een combinatie van verschillende anonimiseer technieken kun je ervoor zorgen dat de kwaliteit van je persoonsgegevens intact blijft, terwijl deze tegelijkertijd niet meer direct herleidbaar zijn naar de persoon aan wie ze toebehoren.
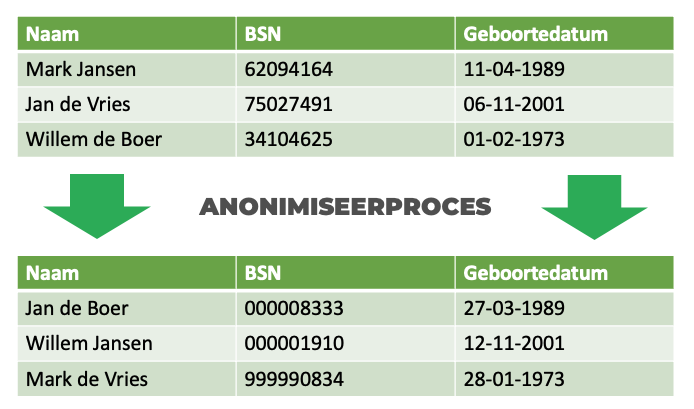
Dit heeft direct twee hele grote voordelen:
Omdat je bestaande productiedata anonimiseert loop je niet het risico dat fictieve gegevens impact hebben op je testproces. Je modificeert namelijk bestaande data die al aan de eisen die je software aan de data stelt voldoet. Dit verkleint het risico op data fouten tijdens het genereren van fictieve data. Daarnaast hoef je niet voor elk testproces zelf fictieve data te bedenken.
En misschien wel het grootste voordeel: voldoende geanonimiseerde data vallen niet onder de AVG.
Om even dieper in te gaan op het laatste voordeel. Als je de persoonsgegevens in je testomgeving zo anonimiseert dat deze niet meer herleidbaar zijn naar de fysieke persoon van wie deze zijn dan is de AVG niet van toepassing. Dit betekent dat er geen doelbinding hoeft te zijn om de geanonimiseerde gegevens te mogen gebruiken en ben je vrij om ze in te zetten voor ieder doel dat je voor ogen hebt. Dat kan dus ook het testen van software zijn.
Via anonimiseren kun je dus zowel voldoen aan de AVG – en specifieke normenkaders zoals de ISO27001/NEN7510 die ook steeds striktere eisen stellen aan het gebruik van persoonsgegevens in niet-productie omgevingen – en zorg je ervoor dat de data waarmee je test productie-like is en blijft. Tegelijkertijd ben je ook beschermt mocht een onbevoegd persoon toegang krijgen tot je testomgeving. Als alle persoonsgegevens anoniem zijn is er geen sprake van een datalek.
Meer weten over anonimiseren binnen je eigen test- en ontwikkelomgevingen?
Bij Privinity ontwikkelen we dataprivacy beschermende oplossingen die je snel en eenvoudig toe kan passen binnen je eigen test- en ontwikkelomgevingen. Zo zijn onze oplossingen te gebruiken op een breed scala aan datatypen, identificeert en categoriseert deze automatisch waar persoonsgegevens binnen je omgeving opgeslagen en gebruikt worden en bieden deze de mogelijkheid om gegevens direct te beschermen door verschillende anonimiseer technieken die per attribuut in te richten zijn.
Benieuwd hoe dat eruit zou kunnen zien binnen je eigen organisatie? Neem contact met ons op voor een Proof of Concept of een demo!
