Anonimiseren, pseudonimiseren, maskeren of de-identificeren?

Er komen heel wat termen voorbij als we het hebben over het beschermen van privacygevoelige gegevens. Veel van deze termen roepen vragen op of zorgen voor verwarring over wat er precies mee bedoeld wordt. Hoog tijd dus om deze veelgebruikte begrippen nader toe te lichten!
Anonimiseren
Laten we beginnen bij de term die we het vaakst gebruiken: anonimiseren. Het anonimiseren van persoonsgegevens houdt in dat de relatie tussen identificeerbare gegevens en de natuurlijke persoon verwijderd wordt. Met identificeerbare gegevens bedoelen we gegevens die mogelijk kunnen leiden tot de identificatie van de betreffende persoon.
De Algemene Verordening Gegevensbescherming (AVG) heeft de volgende definitie aan anonieme gegevens gegeven: “gegevens die geen betrekking hebben op een geïdentificeerde of identificeerbare natuurlijke persoon.” [1]
Identificeerbare gegevens bestaan uit zichzelf in twee categorieën: direct en indirect identificeerbare gegevens.
Direct of indirect identificeerbare gegevens
Met een direct identificeerbaar gegeven kun je aan de hand van alleen die informatie een persoon identificeren. Een voorbeeld hiervan is het BSN-nummer. Iedereen in Nederland heeft een uniek BSN-nummer. Op het moment dat je in het bezit bent van het BSN-nummer, kun je deze dus gebruiken om direct de persoon te herleiden.
Bij indirecte identificeerbare gegevens, ook wel quasi-identifiers genoemd, is een combinatie van gegevens nodig om een persoon te kunnen identificeren. Een voorbeeld van een indirect identificeerbaar gegeven is een postcode. Over het algemeen wonen meerdere personen in hetzelfde postcodegebied, waardoor deze vaak niet tot een directe identificatie van een persoon kan leiden. Als we echter de postcode en ander indirect identificeerbaar gegeven met elkaar combineren, bijvoorbeeld de geboortedatum, is er een grotere kans dat we de persoon kunnen identificeren. Hoeveel personen wonen er bijvoorbeeld in een postcodegebied met geboortedatum 17 januari 1953?
Hoe meer indirect identificeerbare gegevens beschikbaar zijn, hoe groter de kans op identificatie. Uit Amerikaans onderzoek is gebleken dat 87% van de Amerikanen identificeerbaar is door slechts drie indirect identificeerbare gegevens te combineren: postcode, geslacht en geboortedatum [2].
Anonieme gegevens hebben voor organisaties een groot voordeel. Indien de gegevens dermate geanonimiseerd zijn dat deze niet meer (direct of indirect) gebruikt kunnen worden om een natuurlijk persoon te identificeren, dan vallen deze gegevens niet meer onder de AVG wet- en regelgeving. Oftewel, deze gegevens mogen voor alle doeleinden gebruikt worden zonder dat extra maatregelen genomen hoeven te worden.
Maskeren en de-identificeren
Vaak is het doel van anonimiseren dat de gegevens gebruikt kunnen worden voor test-, ontwikkel- en analysedoeleinden. Afhankelijk van de context waarbinnen de gegevens gebruikt worden, zal men moeten bepalen welke gegevens op welke manier beschermd dienen te worden. Het kan dus goed mogelijk zijn dat bepaalde indirect identificeerbare gegevens voor het ene doel anders beschermd worden dan voor een ander doel. Bijvoorbeeld, voor een onderzoek kan het zijn dat met de eisen die aan een geboortedatum gesteld worden alleen het geboortejaar van belang is. In dat geval kan een geboortedatum (14-09-1982) beschermd worden door deze in plaats van de exacte datum te veranderen in alleen het jaar (1982) of te veranderen in een willekeurige datum die binnen het betreffende jaar valt (bijvoorbeeld 26-10-1982 of 03-05-1982).
De keuzes die we maken bij het anonimiseren bepalen de categorie binnen dit mantelbegrip. Hoewel we anonimiseren vaak als een los begrip gebruiken, vallen er onder dit begrip twee verschillende categorieën: maskeren en de-identificeren. Beide anonimiseercategorieën hebben als doel de gegevens te anonimiseren zodat deze niet meer te herleiden zijn naar personen. Echter, het verschil tussen beide categorieën zit in de bruikbaarheid van de gegevens vanuit een analytisch oogpunt.
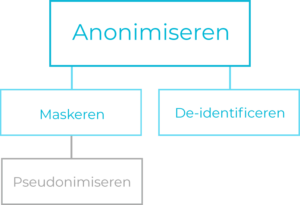
Anonimiseermethoden die onder de categorie maskeren vallen, hebben vaak als doel de gegevens grondig te anonimiseren zonder rekening te houden met de bruikbaarheid van de gegevens na het anonimiseren. Een simpel voorbeeld hiervan is vervangen van een e-mailadres door een vooraf gedefinieerde waarde zoals XXXXXXXXXXX@XXXXXXX.XXX of het compleet verwijderen van het e-mailadres (ook wel generalisatie genoemd). Door deze maskering kan het gegeven niet meer gebruikt worden voor analysedoeleinden. Alle gegevens zijn immers hetzelfde en de nuances in de data zijn verdwenen. Maskeren wordt vaak toegepast op direct identificeerbare gegevens zoals bijvoorbeeld het BSN-nummer.
Bij het anonimiseren doormiddel van de-identificatiemethoden wordt een andere aanpak gebruikt. Hierbij willen we in essentie zorgen dat de gegevens bruikbaar blijven voor bijvoorbeeld analysedoeleinden, terwijl tegelijkertijd de gegevens niet meer te herleiden zijn naar een persoon. Een voorbeeld van de-identificatie is het aanpassen van de precisie van de data, zoals we eerder in het voorbeeld van de geboortedatum hebben beschreven. Een andere methode kan zijn door de waarden in een dataset te verdelen in categorieën. Hierbij valt een persoon met een leeftijd van 33 in de categorie 30 tot 35-jarigen, een persoon met een leeftijd van 18 in de categorie 15 tot 20-jarigen, enzovoort.
Direct identificeerbare gegevens worden vaak gemaskeerd, terwijl de-identificatie vaak wordt toegepast op indirect identificeerbare gegevens.
Pseudonimiseren
Tot nu toe hebben we ons gericht op de term anonimiseren. Naast anonimiseren wordt pseudonimiseren vaak genoemd als methode om persoonsgegevens te beschermen. Anonimiseren en pseudonimiseren staan dicht bij elkaar. Pseudonimiseren is in essentie een vorm van maskeren dat onder anonimiseren valt, echter het doel van beide technieken is wezenlijk verschillend.
Waar anonimiseren tot doel heeft om gegevens zo te beschermen dat deze niet meer gebruikt kunnen om een persoon te identificeren, wordt er bij pseudonimiseren rekening mee gehouden dat de gegevens juist wel herleidbaar kunnen worden gemaakt doormiddel van aanvullende gegevens. De AVG hanteert de volgende definitie van pseudonimiseren: “het verwerken van persoonsgegevens op zodanige wijze dat de persoonsgegevens niet meer aan een specifieke betrokkene kunnen worden gekoppeld zonder dat er aanvullende gegevens worden gebruikt…” 3
Vormen van pseudonimiseren zijn bijvoorbeeld encryptie of het vervangen van een bestaande waarde door een andere (niet-gerelateerde) waarde. Oftewel een pseudoniem.
Een voorbeeld is het vervangen van een BSN-nummer door een pseudoniemwaarde. Zo zou het BSN-nummer 149830751, een fictief nummer ter illustratie, een pseudoniem 5A3GBN97Y kunnen krijgen. Hiermee is het oorspronkelijke BSN-nummer onherkenbaar.
De kracht van pseudonimiseren is dat ieder pseudoniem uniek is voor de originele waarde. Het eerdergenoemde pseudoniem 5A3GBN97Y wordt alleen gebruikt voor BSN-nummer 149830751. Hierdoor blijft het mogelijk om gegevens over verschillende datasets met elkaar te verbinden. Immers, in elke dataset waar het BSN-nummer 149830751 voorkomt wordt deze vervangen door het pseudoniem 5A3GBN97Y. Dit zou niet mogelijk zijn als we voor iedere unieke waarde een willekeurig pseudoniem genereren.
Het andere voordeel van pseudonimiseren is dat het omkeerbaar is. Dat wil zeggen dat het pseudoniem terugvertaald kan worden naar de originele waarde zo lang je de aanvullende gegevens die tot het pseudoniem hebben geleid tot je beschikking hebt. Die aanvullende gegevens kunnen bijvoorbeeld een encryptiesleutel zijn. Heb je de juiste encryptiesleutel, dan kan het pseudoniem vertaald worden naar de originele waarde. Heb je de sleutel niet, dan is er ook geen mogelijkheid om het pseudoniem terug te vertalen.
Pseudonimiseren mag volgens de AVG, zolang de aanvullende gegevens (zoals de encryptiesleutel) apart van de data bewaard worden en er voldoende technische en organisatorische maatregelen genomen zijn om de betreffende aanvullende gegevens te beschermen [3].
[1] “Algemene Verordening Persoonsgegevens”. Artikel 4, overweging 26.
[2] L. Sweeney, “Simple Demographics Often Identify People Uniquely”. Carnegie Mellon University, Data Privacy Working Paper 3.
[3] “Algemene Verordening Persoonsgegevens”. Artikel 4, Definitie 5.

