k-Anonimiteit

Om de data privacy van personen te beschermen gebruiken we vaak het anonimiseren van privacygevoelige gegevens. Door dergelijke gegevens op een goede manier te anonimiseren is een persoon niet direct te identificeren aan de hand van de geanonimiseerde data. Een van de grote uitdagingen op het gebied van anonimiseren is ervoor zorgen dat indirect identificeerbare gegevens alsnog tot een identificatie leiden op het moment dat deze worden gecombineerd.
Indirect identificeerbare gegevens zijn gegevens zoals bijvoorbeeld een postcode, woonplaats of geboortedatum. Op zichzelf leiden deze gegevens niet direct tot een identificatie, maar gecombineerd met andere indirect identificeerbare gegevens kan er een situatie ontstaan die uniek is voor een specifiek persoon. Denk bijvoorbeeld aan een situatie waarbij een woonplaats gecombineerd met een geboortedatum zou kunnen leiden tot de identificatie van de enige 100-jarige in een klein dorp. Om te voorkomen dat het combineren van indirect identificeerbare gegevens het alsnog mogelijk maakt om een persoon te identificeren in een geanonimiseerde dataset kunnen we gebruik maken van een methode genaamd k-anonimiteit.
K-anonimiteit is een methode die voor het eerst geïntroduceerd werd in het onderzoek van Latanya Sweeney in 1998 [1]. K-anonimiteit is een methode die als doel heeft om de identificatie van een persoon aan de hand van een unieke combinatie van indirect identificeerbare gegevens tegen te gaan. Hierbij wordt er uit gegaan dat elke unieke combinatie minimaal k keer voor moet komen in de betreffende dataset. K-anonimiteit is in die zin een voorbeeld van generaliseren. Indien er altijd minimaal k personen zijn die dezelfde kenmerken delen is het niet meer mogelijk om één persoon uit die groep te identificeren.
Bij het anonimiseren van een dataset gebruiken we k-anonimiteit vaak om het geanonimiseerde resultaat te toetsen op re-identificatie van personen. Hierbij zorgen we ervoor dat het anonimiseren op zo’n manier wordt ingericht dat de gewenste k waarde bereikt wordt. Neem bijvoorbeeld de onderstaande – niet-geanonimiseerde – tabel.
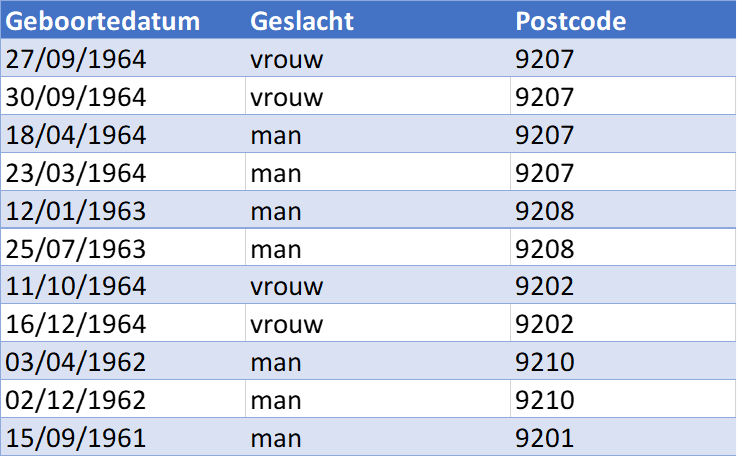
Om deze tabel met een minimale k waarde van 2 te anonimiseren zouden we als eerste ervoor kunnen kiezen om de geboortedatums aan te passen van een exacte datum naar het geboortejaar. Dit zorgt al voor een verbetering zoals in de onderstaande tabel te zien is waarbij de kleuren de groepering op geboortejaar laten zien.
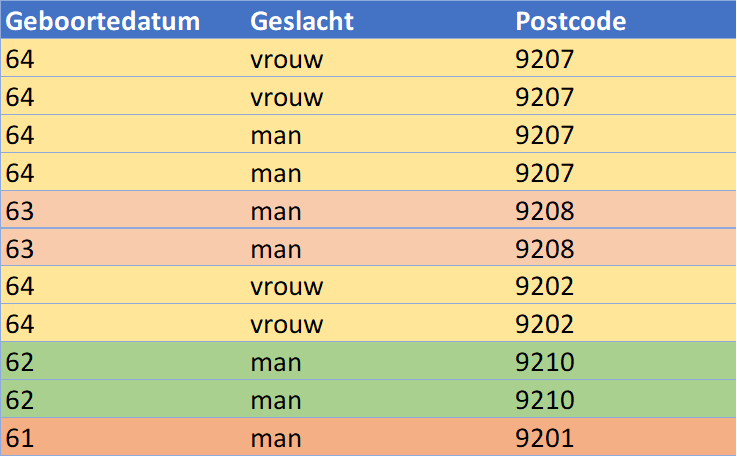
Echter, het resultaat van deze eerste anonimisering voldoet nog niet aan een k-anonimiteit waarbij k 2 is. Zo is er slechts één personen geboren in 61 en heeft deze ook nog een postcode die slechts één keer voorkomt in de tabel. We zouden dit op kunnen lossen door een andere anonimisering uit te voeren. Bijvoorbeeld door de geboortejaren te groeperen in groepen van 5 jaren (61-65) en de postcode minder nauwkeurig te maken door alleen de eerste twee getallen (welke de regio aangeven) terug te laten komen. Het resultaat is onderstaande geanonimiseerde tabel:
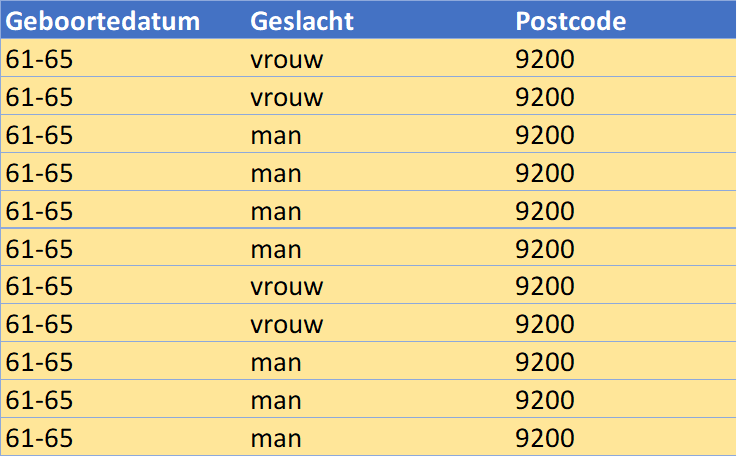
Door deze laatste anonimisering ontstaat er een dataset waarbij één uniek persoon niet meer geïdentificeerd kan worden aan de hand van de beschikbare kenmerken en voldoen we aan de gewenste k waarde (we halen zelfs een k waarde van 4 aangezien elke unieke combinatie minimaal vier keer voorkomt in de tabel).
Hoewel deze voorbeelden een simpele toepassing van k-anonimiteit laten zien wordt het behalen van k-anonimiteit snel moeilijker op het moment dat er sprake is van meer attributen en meer unieke combinaties. Daarnaast speelt het doel waarvoor de data wordt gebruikt ook een grote rol. Stel dat je bijvoorbeeld onderzoek wilt uitvoeren waarvoor het exacte geboortejaar van belang is dan wordt het bereiken van een k waarde van 2 zelfs in deze voorbeelden moeilijk.
Toch zijn er in die situaties nog mogelijkheden te bedenken die het gewenste resultaat geven. Zo zou je er voor kunnen kiezen om de unieke rij uit te tabel te verwijderen of om het geboortejaar van de unieke rij aan te passen naar de gemiddelde waarde wat het onderstaande resultaat geeft. Hierbij wordt de gewenste minimale k waarde van 2 bereikt.
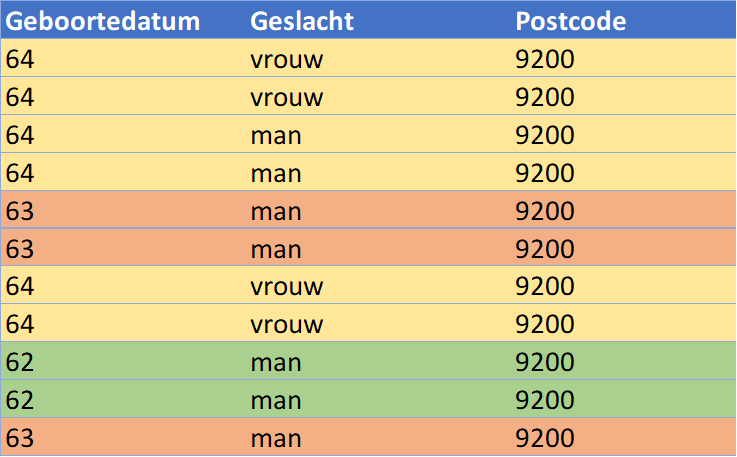
K-anonimiteit is een krachtige methode om de kwaliteit van anonimisering en de kans op re-identificatie te toetsen. Er komt echter veel bij kijken om een k waarde van minimaal 2 te bereiken. Hierbij is het van groot belang om het doel waarvoor de data gebruikt wordt scherp in het oog te houden. De balans tussen anonieme en bruikbare data speelt een grote rol hierbij.
[1] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf

