k-Anonymity

To safeguard the data privacy of individuals, we often employ the anonymization of sensitive information. By anonymizing such data effectively, a person cannot be directly identified based on the anonymized data. One of the significant challenges in anonymization is ensuring that indirectly identifiable data still leads to identification when combined.
Indirectly identifiable data includes information such as a postal code, place of residence, or date of birth. On their own, these data points do not immediately lead to identification, but when combined with other indirectly identifiable data, a situation unique to a specific individual may arise. For instance, combining a place of residence with a date of birth could potentially lead to identifying the only 100-year-old in a small village. To prevent the combination of indirectly identifiable data from allowing the identification of a person in an anonymized dataset, we can employ a method called k-anonymity.
K-anonymity is a method first introduced in the research of Latanya Sweeney in 1998 [1]. The goal of k-anonymity is to counteract the identification of a person based on a unique combination of indirectly identifiable data. The method assumes that each unique combination should occur at least k times in the respective dataset. In this sense, k-anonymity is an example of generalization. If there are always at least k individuals sharing the same characteristics, it becomes impossible to identify a single person from that group.
When anonymizing a dataset, we often use k-anonymity to assess the anonymized result for the re-identification of individuals. In this process, we ensure that the anonymization is configured in such a way that the desired k value is achieved. Consider the following, non-anonymized table as an example.
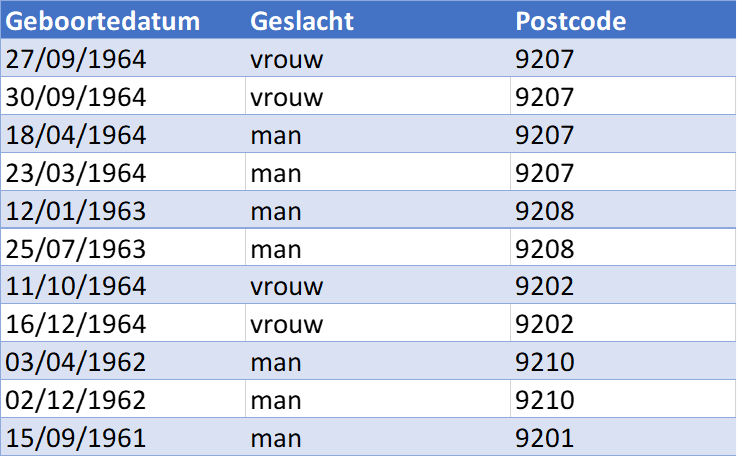
To anonymize this table with a minimum k value of 2, we could first choose to adjust the birthdates from an exact date to the birth year. This already improves the situation, as shown in the table below, where colors indicate grouping by birth year.
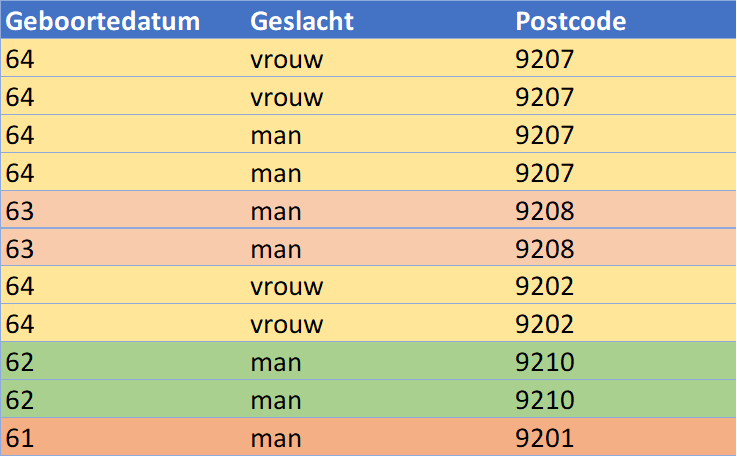
However, the result of this initial anonymization does not yet meet a k-anonymity with k equal to 2. For instance, there is only one person born in ’61, and this person also has a postal code that appears only once in the table. We could address this by performing another anonymization, such as grouping the birth years in intervals of 5 years (61-65) and making the postal code less precise by retaining only the first two digits (indicating the region). The result is the anonymized table below:
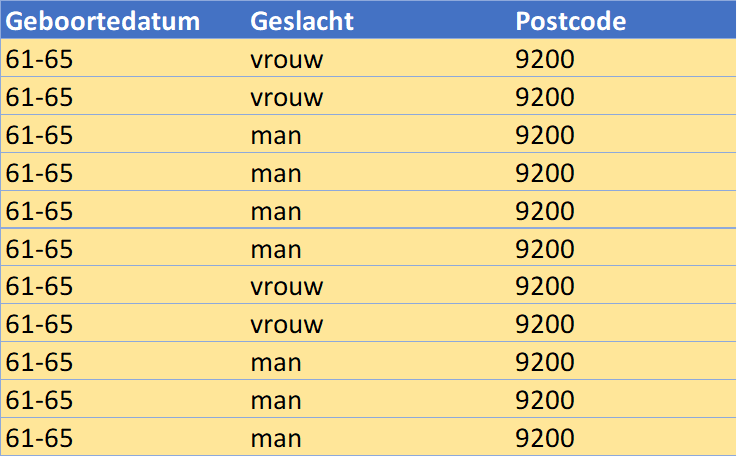
Through this final anonymization, a dataset is created where one unique individual can no longer be identified based on the available characteristics, and we meet the desired k value (in fact, achieving a k value of 4 as each unique combination occurs at least four times in the table).
While these examples illustrate a simple application of k-anonymity, achieving k-anonymity becomes challenging as more attributes and unique combinations come into play. Additionally, the purpose for which the data is used plays a significant role. For instance, if you need to conduct research where the exact birth year is crucial, achieving a k value of 2 can be difficult, even in these examples.
Nevertheless, there are still options in such situations to achieve the desired result. For instance, you could choose to remove the unique row from the table or adjust the birth year of the unique row to the average value, resulting in the outcome below. This satisfies the desired minimum k value of 2.
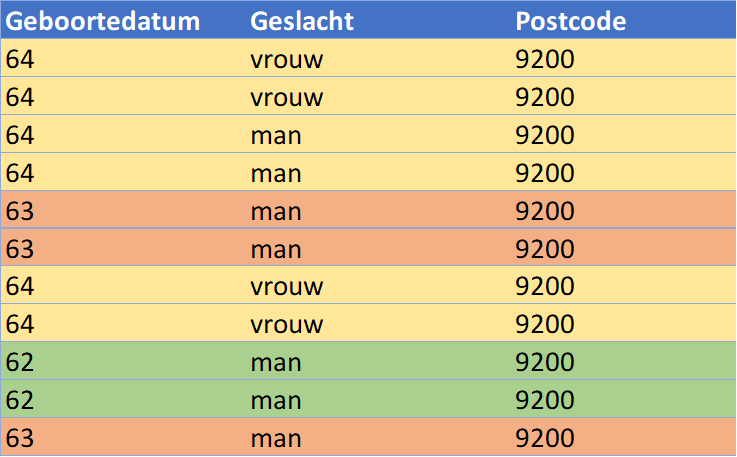
K-anonymity is a powerful method to assess the quality of anonymization and the risk of re-identification. However, achieving a minimum k value of 2 requires careful consideration, particularly keeping the purpose of the data usage in mind. Striking a balance between anonymous and usable data is crucial in this context.
[1] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf

