Wat is pseudonimiseren en wat maakt het anders dan anonimiseren?

Anonimiseren en pseudonimiseren zijn twee termen die vaak samen, en door elkaar, gebruikt worden op het moment dat we het hebben over het beschermen van privacygevoelige gegevens. Hoewel beide termen vaak gebruikt worden om hetzelfde proces te duiden, zijn het twee totaal verschillende beschermingsmethoden die je op verschillende manieren en situaties toepast.
Anonimiseren heeft als primair doel om gegevens op een manier te beschermen zodat deze niet meer gebruikt kunnen worden om een persoon binnen een dataset te identificeren. Dit kan bijvoorbeeld door specifieke attributen onleesbaar te maken door ze te vervangen met “X”-en, of door bestaande attributen op zo’n manier aan te passen dat ze niet meer gebruikt kunnen worden om de originele persoon te herleiden. Een belangrijk kenmerk van anonimiseren is dat het onomkeerbaar moet zijn. Oftewel, de geanonimiseerde waarde mag nooit meer getransformeerd kunnen worden naar de originele waarde via technische methoden en technieken.
Pseudonimiseren verschilt van anonimiseren omdat bij het toepassen van pseudonimiseren de originele persoon nog steeds indirect identificeerbaar is. Dit komt met name door de manieren waarop we pseudonimiseren toepassen.
Gepseudonimiseerde data blijft koppelbaar
In veel gevallen wordt pseudonimiseren toegepast op een – direct identificeerbaar – sleutelveld van een dataset, bijvoorbeeld een BSN-nummer. Het doel hiervan is om het bestaande, originele, BSN-nummer te vervangen voor een uniek pseudoniem. Een voorbeeld hiervan is zou kunnen zijn dat het BSN-nummer 149830751 vervangen wordt door het pseudoniem 5A3GBN97Y.
Een toepassing waarin pseudonimiseren vaak wordt toegepast is om verschillende datasets koppelbaar te houden aan elkaar. Wat we hiermee bedoelen is dat twee verschillende datasets beide een unieke sleutelwaarde hebben – zoals een BSN-nummer – waarop beide datasets aan elkaar gekoppeld kunnen worden. Indien we het BSN-nummer zouden anonimiseren dan zou het BSN-nummer transformeren in een verschillende waarde voor beide datasets waardoor deze niet meer aan elkaar te koppelen zijn.
Omdat pseudonimiseren in de meeste gevallen gebaseerd is op een encryptie en/of hashing methode is het mogelijk om het BSN-nummer in beide datasets hetzelfde – identieke – pseudoniem voor het BSN-nummer te geven. Hierdoor blijven beide datasets aan elkaar te koppelen. De afbeelding hieronder illustreert deze koppeling van gepseudonimiseerde sleutelvelden.
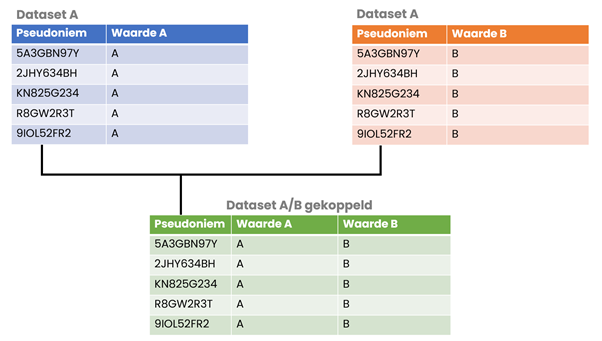
Het koppelbaar houden van verschillende datasets kan veel meerwaarde hebben voor bijvoorbeeld onderzoeksdoeleinden waarbij één partij een deel van de data aanlevert en andere partijen deze aanvult en verrijkt met de informatie die in hun bezit is. Dit proces gebeurt zowel intern, bijvoorbeeld in een data warehouse, maar ook extern.
Pseudonimiseren toepassen om te herleiden
In sommige gevallen wordt pseudonimiseren toegepast om herleiding naar de originele persoon juist mogelijk te maken. Een vaak genoemde toepassing hierbij is het terugrekenen van een pseudoniem omdat het van groot belang is voor de persoon waaraan het pseudoniem gekoppeld is. Denk hierbij bijvoorbeeld aan medisch onderzoek waaruit naar boven komt dat een specifiek pseudoniem een aandoening heeft waarbij snel informeren van belang is. In dit geval wil je het pseudoniem dus terug kunnen herleiden naar de direct identificeerbare waarde zodat je de betreffende persoon kan informeren. Aan deze situatie zitten additioneel nog strenge processen verbonden. Zo mag in dit voorbeeld alleen de behandelaar van de persoon in kwestie het pseudoniem terugrekenen naar de originele waarde en niet de onderzoeker.
Maatregelen om pseudonimiseren veilig toe te passen
Zoals we al eerder in dit artikel schreven is het gebruik van pseudonimiseren om direct identificeerbare waardes te beschermen op zichzelf niet veilig genoeg. Door het pseudonimiseren verander je wel de waarde maar deze kan nog steeds voor identificatie doeleinden gebruikt worden. Om die reden wil je pseudonimiseren alleen toepassen op het moment dat je er een daadwerkelijke noodzaak voor hebt en gebruik je het altijd in combinatie met het anonimiseren van de overige privacy gevoelige gegevens.
Om pseudonimiseren veilig toe te passen vraagt de wet- en regelgeving aanvullende maatregelen. Deze maatregelen zijn met name gericht om ervoor te zorgen dat het zonder aanvullende gegevens niet mogelijk moet zijn om het pseudoniem terug te transformeren naar de originele waarde. Als je bijvoorbeeld een encryptie methode gebruikt zal je er voor moeten zorgen dat de sleutel die gebruikt wordt om de originele waarde naar het pseudoniem te transformeren maximaal beschermt wordt. Als je namelijk deze sleutel hebt kun je het pseudoniem gemakkelijk terugrekenen. Daarnaast zal je ook toegangscontrole en logging op dergelijke sleutels willen inrichten zodat je onrechtmatig gebruik snel kan identificeren. Een andere manier is om de sleutel slechts éénmalig te gebruiken en deze dan te verwijderen. Dit zorgt er echter wel voor dat het terugrekenen naar de originele waarde niet meer mogelijk is aangezien de gebruikte sleutel niet meer bestaat. In het geval van hashing methodes wil je ervoor zorgen dat de betreffende methode veilig genoeg is. Zo is een populaire hashing methode MD5 al een hele tijd onveilig omdat het mogelijk is om de gegenereerde hash waardes relatief snel via “brute force” aanvallen te breken.

