What is pseudonymization, and how does it differ from anonymization?

Anonymization and pseudonymization are two terms often used interchangeably when discussing the protection of sensitive data. While both terms are commonly used to refer to the same process, they represent two entirely different methods of safeguarding data, applied in different ways and situations.
Anonymization primarily aims to protect data in a way that it can no longer be used to identify a person within a dataset. This can be achieved by making specific attributes unreadable, replacing them with “X”s, or modifying existing attributes in a way that prevents the original person from being traced. An essential characteristic of anonymization is its irreversibility. In other words, the anonymized value should never be transformable back to the original value through technical methods and techniques.
Pseudonymization differs from anonymization because, when applying pseudonymization, the original person remains indirectly identifiable. This is primarily due to the ways in which pseudonymization is applied.
Pseudonymized data remains linkable
In many cases, pseudonymization is applied to a directly identifiable key field in a dataset, such as a social security number (BSN in Dutch). The goal is to replace the existing, original BSN with a unique pseudonym. An example could be replacing the BSN 149830751 with the pseudonym 5A3GBN97Y.
Pseudonymization is often used to keep different datasets linkable to each other. This means that two different datasets both have a unique key value, such as a BSN, on which both datasets can be linked. If we were to anonymize the BSN, the BSN would transform into a different value for both datasets, making them no longer linkable.
Because pseudonymization is often based on an encryption and/or hashing method, it is possible to assign the same identical pseudonym to the BSN in both datasets. This allows both datasets to remain linked. The image below illustrates this linking of pseudonymized key fields.
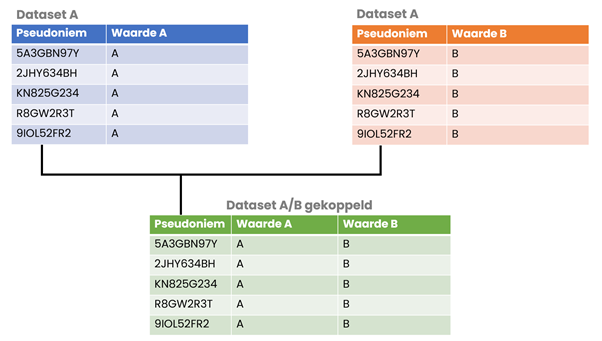
Maintaining the linkability of different datasets can provide significant value, especially for research purposes where one party contributes part of the data, and other parties complement and enrich it with their information. This process occurs both internally, for example, in a data warehouse, and externally.
Applying pseudonymization for traceability
In some cases, pseudonymization is applied to enable traceability back to the original person. A commonly mentioned application is the reverse calculation of a pseudonym, crucial for the person associated with it. Consider, for instance, medical research revealing that a specific pseudonym corresponds to a condition where prompt notification is essential. In this scenario, you want to trace the pseudonym back to the directly identifiable value to inform the relevant person. Additional stringent processes are attached to this situation. For example, only the individual’s healthcare provider, not the researcher, is permitted to reverse-calculate the pseudonym in this case.
Measures to safely apply pseudonymization
As previously mentioned in this article, using pseudonymization to protect directly identifiable values is not secure enough on its own. Pseudonymization alters the value, but it can still be used for identification purposes. For this reason, you should only apply pseudonymization when there is a genuine necessity and always use it in conjunction with the anonymization of other privacy-sensitive data.
To safely implement pseudonymization, legal and regulatory requirements necessitate additional measures. These measures primarily focus on ensuring that it is not possible to transform the pseudonym back into the original value without additional data. For example, if you use an encryption method, you must ensure that the key used to transform the original value into the pseudonym is maximally protected. Possession of this key would easily allow the pseudonym to be reverse-calculated. Additionally, you would want to establish access control and logging on such keys to promptly identify any unauthorized use. Another approach is to use the key only once and then delete it. However, this means that reversing to the original value is no longer possible since the used key no longer exists. In the case of hashing methods, you want to ensure that the specific method is secure enough. For instance, the popular MD5 hashing method has been considered insecure for a while because it is possible to break the generated hash values relatively quickly through “brute force” attacks.

