Wat is anonimiseren en hoe pas je het toe?

Anonimiseren is een van de meest veilige manieren om privacygevoelige gegevens te beschermen. Persoonsgegevens die voldoende geanonimiseerd zijn vallen namelijk niet meer onder de AVG wet- en regelgeving waardoor je deze voor ieder doel mag gebruiken. Maar wat is anonimiseren nu precies, en hoe zorg je er dan voor dat persoonsgegevens voldoende geanonimiseerd zijn?
Anonimiseren is het proces waarbij je ervoor zorgt dat de gegevens van een persoon op een dermate manier aangepast worden zodat deze niet meer gebruikt kunnen worden om de betreffende persoon te identificeren. Anonimiseren kan zo makkelijk zijn als identificeerbare gegevens onleesbaar maken, bijvoorbeeld door met een zwarte stift de geboortedatum van een persoon in een document door te strepen. Hierdoor is de geboortedatum van de betreffende persoon niet meer te gebruiken als informatie om de persoon te identificeren. De keerzijde van deze manier van anonimiseren is dat de onleesbare geboortedatum helemaal niet meer bruikbaar is. Op zich geen probleem op het moment dat de geboortedatum in een document wordt “gemaskeerd” maar er ontstaat mogelijk wel een probleem als de geboortedatum een essentieel onderdeel van bijvoorbeeld een bevolkingsonderzoek is.
Stel dat je in een dergelijk onderzoek wilt weten hoeveel personen er in een specifieke regio wonen met een leeftijd tussen de 30 en 40, dan is een onleesbare geboortedatum niet bruikbaar. In dit geval zou mogelijk alleen de dag en maand van de geboortedatum anonimiseren voldoende kunnen zijn om ervoor te zorgen dat de datum niet gebruikt kan worden om te persoon te identificeren en tegelijkertijd deze bruikbaar blijft voor het onderzoek.
In deze twee voorbeelden schetsen we ook al gelijk de belangrijkste uitdaging van het anonimiseren. Hoe zorg je ervoor dat de geanonimiseerde gegevens niet gebruikt kunnen worden om een persoon te identificeren en tegelijkertijd bruikbaar blijven voor het doel waarvoor je ze anonimiseert? En waarom zou je daar zoveel moeite voor doen?
Waarom ga je anonimiseren?
Globaal gezien zijn er twee redenen waarom organisaties persoonsgegevens anonimiseren:
- Omdat ze het belangrijk vinden om de privacy van de personen waarover ze gegevens verwerken te beschermen;
- Om te voldoen aan de wet- en regelgeving van de Algemene Verordening Gegevensbescherming (AVG).
De AVG stelt strikte eisen aan het werken met persoonsgegevens. Zo mag je namelijk niet zomaar persoonsgegevens verzamelen en verwerken zonder een goede reden en moet je aantoonbaar maatregelen nemen om ze te beschermen. Het grote voordeel van geanonimiseerde gegevens is – als ze voldoende anoniem zijn – deze niet meer onder de AVG wet- en regelgeving vallen. Er kan namelijk geen persoon meer geïdentificeerd worden vanuit de geanonimiseerde dataset. Hierdoor kun je dus in essentie de gegevens voor ieder doel gebruiken zonder dat je hier verdere maatregelen voor hoeft te nemen.
Wat is voldoende anoniem?
Volgens de wet- en regelgeving zijn anonieme gegevens, gegevens die: “geen betrekking hebben op een geïdentificeerde of identificeerbare natuurlijke persoon of op persoonsgegevens die zodanig anoniem zijn gemaakt dat de betrokkene niet of niet meer identificeerbaar is”. [1]
Vaak toetsen we een anoniem resultaat aan de hand van drie criteria:
- Herleidbaarheid, oftewel de mogelijkheid om een persoon direct te identificeren;
- Koppelbaarheid, de mogelijkheid om andere gegevens in verband te brengen met een persoon wat tot een identificatie kan leiden;
- Deduceerbaarheid, de mogelijkheid om informatie af te leiden wat gebruikt kan worden om een persoon te identificeren.
Op het moment dat een toetsing van de drie bovenstaande criteria dus niet kan leiden tot een identificatie van een persoon dan kun je concluderen dat de data voldoende anoniem is.
Vormen van anonimiseren
Hoe ga je er dan uiteindelijk voor zorgen dat je data niet meer gebruikt kan worden om een persoon te identificeren aan de hand van de bovenstaande criteria? Daar komt het anonimiseren om te hoek kijken.
Doormiddel van anonimiseren zorg je ervoor dat de gegevens die gebruikt kunnen worden om een persoon te identificeren op een dermate manier aangepast worden dat deze niet meer gebruikt kunnen worden voor een daadwerkelijke identificatie. In de introductie van dit artikel noemde we al de voorbeelden om een geboortedatum te maskeren of aan te passen naar een andere precisie, maar er zijn nog veel meer manieren om data te anonimiseren.
Welke van de manieren die je kiest, en op welke data je ze toepast, hangt sterk af van het doel dat je hebt met de data. We kunnen in die zin dus niet uitgaan van een “one size fits all” configuratie op het gebied van anonimiseren. Om een idee te geven wat er allemaal mogelijk is qua anonimiseren zetten we een aantal anonimiseer categorieën en methoden op een rijtje samen met een aantal voorbeelden hoe je ze toe zou kunnen passen.
Maskeren
Maskeren is een van de meest directe vormen van anonimiseren. Doormiddel van maskeren vervang je de originele waarde door deze onleesbaar of onbruikbaar te maken. Denk bijvoorbeeld aan het vervangen van de originele waarde door een waarde met alle “X”-en.
Maskeren heeft als groot nadeel dat de data – doordat deze onleesbaar/onbruikbaar is gemaakt – niet meer bruikbaar is voor analyse doeleinden. Aan de andere kant biedt het een grote mate van anonimisering. Vaak wordt maskeren toegepast op waardes die direct tot een identificatie kunnen leiden, bijvoorbeeld een BSN-nummer of een paspoortnummer.
Generaliseren
Generaliseren is een anonimiseercategorie waar ook maskeren in essentie onder valt. Bij generaliseren zorg je er eigenlijk voor dat alle waarden identiek worden waardoor een uniek gegeven niet meer kan leiden tot een identificatie. Een voorbeeld hiervan is het aanpassen van alle voornamen naar dezelfde naam, of iedereen dezelfde geboortedatum geven.
Een andere techniek binnen generaliseren is het aanpassen van de schaalgrootte, of omvang, van een gegeven. Bijvoorbeeld door een stad te vervangen door een provincie, of door een exacte geboortedatum aan te passen naar een geboortejaar.
Randomiseren
Bij randomiseren pas je de gegevens op een onvoorspelbare manier aan zodat deze verschillen van de originele waarde. Binnen de randomiseer categorie zijn er eigenlijk twee technieken die veel gebruikt worden: het toevoegen van zogenaamde “ruis”, of het opnieuw ordenen van specifieke waardes binnen een persoonskenmerk. Dit laatste noemen we formeel “permutatie” maar wordt ook vaak genoemd als het “husselen” van kenmerken.
Bij het toevoegen van ruis passen we de originele waarde aan zodat deze minder nauwkeurig wordt. Bijvoorbeeld: een persoon is op 14-09-1982 geboren, we kiezen vervolgens een willekeurig getal tussen de -10 en +10 en aan de hand van de geselecteerde waarde passen we de bestaande datum aan. Stel dus dat er als waarde -8 wordt gekozen dan wordt de originele geboortedatum aangepast naar 06-09-1982.
Bij permutatie maken we gebruik van de bestaande waarde in een dataset. Denk bijvoorbeeld aan een kolom waarin voornamen geregistreerd staan. Door een permutatie gaan we de voornamen willekeurig verwisselen zodat uiteindelijk ieder persoon in de dataset van een andere voornaam wordt voorzien. Op het moment dat we dit op voldoende kenmerken doorvoeren (achternaam, woonplaats, etc.) ontstaan er eigenlijk nieuwe – fictieve – personen die bestaan uit de kenmerken van de bestaande personen in de dataset.
Pseudonimiseren
Een andere techniek die veel toegepast wordt is pseudonimiseren. Pseudonimiseren is echter geen anonimiseermethode omdat het eigenlijk een bestaand attribuut vervangt door een nieuwe – unieke – waarde die nog steeds aan de originele persoon te koppelen is (denk bijvoorbeeld aan het genereren van een hash/encryptie waarde van het BSN-nummer van een persoon).
Ook al is pseudonimiseren niet op zichzelf een manier om persoonsgegevens in een dataset voldoende te beschermen, het kan wel bijdragen aan de bruikbaarheid van de data. In dit artikel gaan we dieper in op het begrip pseudonimiseren.
Voorbeeld van een geanonimiseerde dataset
Om een idee te geven hoe je een dataset zou kunnen anonimiseren met de verschillende technieken die we hierboven hebben beschreven gebruiken we de onderstaande voorbeeld “dataset”. In dit geval is het niet meer dan een simpele tabel met een aantal fictieve persoonsgegevens, maar dit is voldoende om de concepten te illustreren.
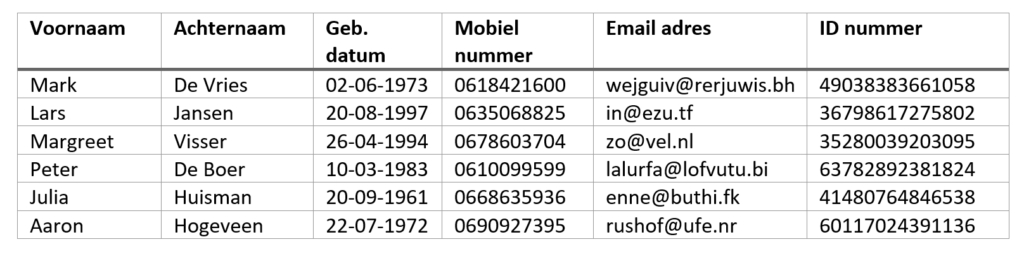
Stel nu dat we deze dataset willen anonimiseren maar we willen het geboortejaar gebruiken voor onderzoek. De andere gegevens worden in principe niet gebruikt. Een anonimiseerinrichting zou er dan als volgt uit kunnen zien:

Het resultaat van het anonimiseren zou een tabel op kunnen leveren die er als volgt uitziet:
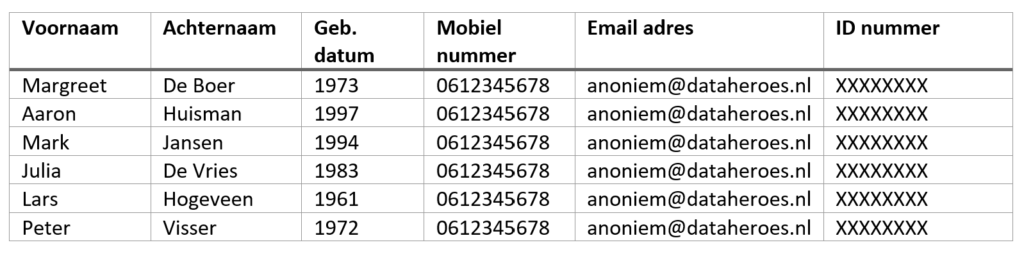
In dit geval hebben we het generaliseren toegepast door simpelweg de geboortedag en de geboortemaand te verwijderen en alleen het jaar te laten staan. Op die manier is dit persoonsgegeven nog steeds bruikbaar, maar is het niet dermate gedetailleerd dat het gebruikt zou kunnen worden voor een identificatie op zichzelf[2]. Andere gegevens zijn gerandomiseerd (Voornaam en Achternaam) en gegeneraliseerd zodat deze allemaal identiek zijn (Mobiel nummer, Email adres, ID nummer).
[1] AVG Grond 26, https://www.privacy-regulation.eu/nl/grond-26-EU-AVG.htm
[2] Voor dit voorbeeld laten we bewust even additionele anonimiteitstoetsen via bijvoorbeeld k-anonimiteit, l-diversiteit en t-gelijkenis achterwege.

