What is anonymizing and how do you apply it?

Anonymizing is one of the most secure methods to safeguard sensitive data. Personal data that is adequately anonymized no longer falls under the regulations of the General Data Protection Regulation (GDPR), allowing you to use it for any purpose. But what exactly is anonymization, and how do you ensure that personal data is sufficiently anonymized?
Anonymization is the process by which you ensure that a person’s data is modified in such a way that it can no longer be used to identify the respective individual. Anonymization can be as simple as making identifiable information unreadable, for example, by crossing out a person’s date of birth in a document with a black marker. As a result, the date of birth of the individual in question is no longer usable as information to identify the person. The downside of this method of anonymization is that the unreadable date of birth becomes entirely unusable. This is not a problem per se when the date of birth in a document is “masked,” but a potential issue may arise if the date of birth is an essential part of, for example, a population study.
Imagine you are conducting such a study and want to determine the number of individuals living in a specific region between the ages of 30 and 40. In this case, an unreadable date of birth is not useful. In such situations, anonymizing only the day and month of the birthdate may be sufficient to ensure that the date cannot be used to identify the person while still remaining useful for the research.
In these two examples, we also immediately highlight the main challenge of anonymization. How do you ensure that the anonymized data cannot be used to identify a person while remaining useful for the purpose for which you are anonymizing them? And why would you go through all that trouble?
Why do you anonymize personal data?
Generally, there are two reasons why organizations anonymize personal data:
- Because they consider it important to protect the privacy of the individuals whose data they process;
- To comply with the laws and regulations of the General Data Protection Regulation (GDPR).
The GDPR imposes strict requirements on processing personal data. Collecting and processing personal data without a valid reason is not allowed, and organizations must demonstrably take measures to protect such data. The big advantage of anonymized data is that, if adequately anonymized, it falls outside the scope of the GDPR laws and regulations. Once data is anonymized to a sufficient extent, it becomes impossible to identify individuals from the anonymized dataset. Consequently, you can essentially use the data for any purpose without needing further protective measures.
What is considered adequately anonymous?
According to laws and regulations, anonymous data refers to data that “does not relate to an identified or identifiable natural person or to personal data that have been made anonymous in such a way that the data subject is not or no longer identifiable.” [1]
We often assess an anonymous result based on three criteria:
- Traceability, which is the ability to directly identify a person;
- Linkability, the ability to link other data to a person which can lead to identification;
- Deductibility, the possibility to deduce information that could be used to identify a person.
If an evaluation of the above three criteria cannot lead to the identification of a person, then it can be concluded that the data is sufficiently anonymous.
Methods of anonymization
How do you ultimately ensure that your data cannot be used to identify a person based on the above criteria? This is where anonymization comes into play.
Through anonymization, you modify the data that could be used to identify a person in such a way that it can no longer be used for actual identification. In the introduction of this article, we already mentioned examples such as masking or adjusting a birthdate to a different precision, but there are many more ways to anonymize data.
Welke van de manieren die je kiest, en op welke data je ze toepast, hangt sterk af van het doel dat je hebt met de data. We kunnen in die zin dus niet uitgaan van een “one size fits all” configuratie op het gebied van anonimiseren. Om een idee te geven wat er allemaal mogelijk is qua anonimiseren zetten we een aantal anonimiseer categorieën en methoden op een rijtje samen met een aantal voorbeelden hoe je ze toe zou kunnen passen.
The choice of methods and the data to which you apply them depend heavily on the goal of processing specific data. In that sense, we cannot assume a “one size fits all” configuration in the field of anonymization. To give you an idea of what is possible in terms of anonymization, we list several anonymization categories and methods along with examples of how you might apply them.
Masking
Masking is one of the most direct forms of anonymization. By masking, you replace the original value with an unreadable or unusable representation. For example, consider replacing the original value with a string of “X”s.
The major drawback of masking is that the data, being made unreadable or unusable, becomes impractical for analytical purposes. On the other hand, it provides a high level of anonymization. Masking is often applied to values that could directly lead to identification, such as a social security number or a passport number.
Generalization
Generalizing is an anonymization method that essentially includes masking. With generalizing, you make all values identical, preventing a unique piece of information from leading to identification. An example of this is changing all first names to the same name or assigning everyone the same birthdate.
Another technique within generalizing involves adjusting the scale or scope of a piece of information. For instance, replacing a city with a state/region or modifying an exact birthdate to a birth year.
Randomization
With randomizing, you adjust the data in an unpredictable manner, making it differ from the original value. Within the randomizing category, there are two commonly used techniques: adding “noise” or rearranging specific values within a personal characteristic. The latter is formally known as “permutation” but is also often referred to as “shuffling” characteristics.
When adding noise, we adjust the original value to make it less precise. For example, if a person was born on 14-09-1982, we randomly select a number between -10 and +10. Based on the chosen value, we then adjust the existing date. If, for instance, -8 is selected, the original birthdate is modified to 06-09-1982.
In permutation, we utilize the existing values in a dataset. Consider a column containing first names. Through permutation, we randomly swap the first names so that ultimately, each person in the dataset is assigned a different first name. When applied to sufficient characteristics (last name, place of residence, etc.), this creates new – fictional – individuals composed of the features of the existing individuals in the dataset.
Pseudonymizing
Another technique commonly applied is pseudonymizing. However, pseudonymizing is not an anonymization method in itself because it essentially replaces an existing attribute with a new – unique – value that can still be linked to the original person (think, for example, of generating a hash/encryption value of a person’s social security number).
Even though pseudonymizing alone is not a method to sufficiently protect personal data in a dataset, it can contribute to the usability of the data. In this article, we delve deeper into the concept of pseudonymizing.
Example of an anonymized dataset
To give an idea of how you could anonymize a dataset using the various techniques described above, we use the example “dataset” below. In this case, it is nothing more than a simple table with some fictional personal data, but it is sufficient to illustrate the concepts.
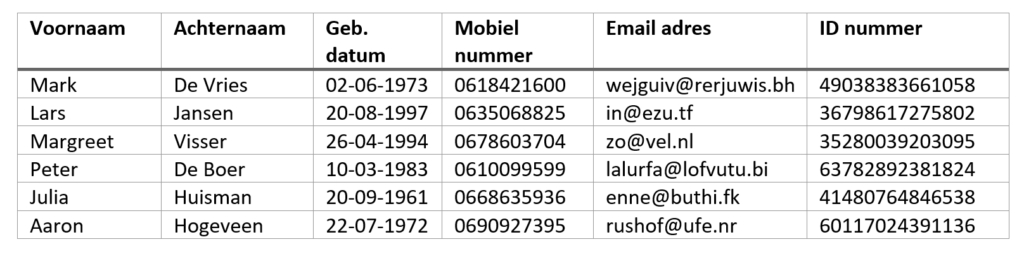
Suppose we want to anonymize this dataset, but we want to use the birth year for research. The other data is not essentially used. An anonymization setup could look like this:

The result of the anonymization could lead to a table that looks like this:
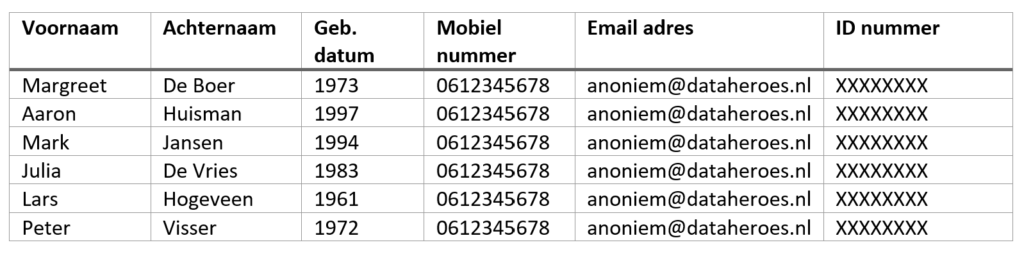
In this case, we applied generalization by simply removing the birth day and month, leaving only the year. This way, this personal data is still usable, but it is not detailed enough to be used for identification on its own[2]. Other data is randomized (First Name and Last Name) and generalized so that they are all identical (Mobile Number, Email Address, ID Number).
[1] GDPR Recital 26, https://www.privacy-regulation.eu/en/r26.htm
[2] For this example, we deliberately omit additional anonymity tests such as k-anonymity, l-diversity, and t-similarity.

